The Personal Website of Mark W. Dawson

Containing His Articles, Observations, Thoughts, Meanderings,
and some would say Wisdom (and some would say not).
Beware of Computer Modeling and Statistical Processing
In the early computer age, there was an expression “Garbage In = Garbage Out” (GIGO) that, in actuality, should have been “Garbage In and/or Garbage Processing = Garbage Out” (GIGPGO). In more general and rigorous terms, it is:
Data In + Data Processing = Data Out
Each stage of Data In, Data Processing, and Data Out has potential problems that can lead to errors. This is most especially true in Computer Modeling and Statistical Processing, where errors are commonplace and incorrect Data Out can lead to extremely unfortunate or dire consequences.
Computer Modeling and Statistical Processing can be done in a linear and non-linear manner. The main difference between linear and non-linear computer models is that linear models make a prediction using a linear function of the input features, while non-linear models use a non-linear function. It is important to know the difference between these two types of models because the choice of a linear or non-linear model can greatly impact the model’s performance and the interpretability of the results. The primary distinction between linear and non-linear models is the nature of their predictions. Linear models employ a linear function of input features, resulting in a consistent slope or a straight line when plotted on a graph. Conversely, non-linear models utilize a non-linear function, resulting in a varying slope or a curved line when plotted. The differences between Linear and Non-Linear Models are:
|
Linear Models |
Non-Linear Models |
|
Make predictions using a linear function of the input features |
Make predictions using a non-linear function of the input features |
|
Have a constant slope |
Have a varying slope |
|
The relationship between input and output is additive |
The relationship between input and output is multiplicative or exponential |
|
Generally easy to interpret |
Generally harder to interpret |
|
Perform well when the relationship between input and output is approximately linear |
Perform well when the relationship between input and output is non-linear |
|
Examples: Linear Regression, Logistic Regression |
Examples: Decision Trees, Neural Networks, Support Vector Machines |
In the field of Computer Modeling and Statistical Processing, there’s a fundamental difference between static and dynamic models. Static models assume that the relationships in the data remain constant over time, while Dynamic Models take into account the ever-evolving nature of these relationships. This distinction is crucial as the choice of model can greatly affect the accuracy and practicality of predictions. The difference Between Static and Dynamic Models are:
|
Feature |
Static Models |
Dynamic Models |
|
Definition |
Assumes relationships in data are fixed and do not change over time |
Takes into account the ever-changing nature of relationships in data |
|
Use case |
Appropriate for data with stable relationships |
Appropriate for data with changing relationships |
|
Advantages |
Simple to implement, easy to understand |
Can provide more accurate predictions, better at handling non-stationary data |
|
Disadvantages |
Can be less accurate when relationships change |
More complex to implement and understand |
The other type of model is a Non-deterministic model, which unlike deterministic models, can produce different outputs for the same inputs depending on the specific circumstances or conditions under which the model is run. These types of models involve randomness or probability and are often used to model systems that are inherently uncertain or unpredictable. One of the main advantages of non-deterministic models is that they can more accurately reflect the complexity and uncertainty of real-world systems. Another advantage of non-deterministic models is that they can provide a range of possible outcomes or solutions, rather than a single fixed result. However, non-deterministic models also have some limitations., as one of the main challenges is that they can be difficult to test and validate, since the specific outcome of a given run of the model cannot be predicted with certainty. Additionally, non-deterministic models can be computationally expensive, as they often involve large amounts of random sampling and trial-and-error. There are several different types of non-deterministic models; Stochastic models, Neural Networks, and Genetic Algorithms, each with their own unique characteristics and applications.
Note: the information on Static, Dynamic, and Non-Deterministic models is from the website MathVsWild.com, which I highly recommend for a basic introduction to Discrete Mathematics.
Some of the general commonplace problems of Computer Modeling and Statistical Processing are:
Problems with Data In
- Accuracy of Data
In all of science and engineering, the more accurate the data, the more accurate the science and engineering. This has to do with the granularity of the size and time of your measurements. After all, if you are going to measure the size of a fly, you need to have a measuring instrument that can measure much less than one inch, and if you are going to measure the time it takes a fly to go from point a to b for short distances you need a stopwatch that can measure time in less than a second; otherwise, the data you collect will not be accurate enough to be usable. - Quality of Data
Data quality is the criteria used to evaluate the data for accuracy, completeness, validity, consistency, uniqueness, timeliness, and fitness for purpose. Much of the initial quality of data is related to the Sample Size, Random Sampling, and Margin of Error of the collected data. If any one of these three items is improper, the quality of the data is highly suspect and, therefore, the Data Out is highly suspect. - Manipulation or Massaging of Input Data
Data may come from many different sources and in many different formats that need to be manipulated and/or message to make the data consistent so that it can be utilized by the Data Processing. Great care must be utilized in manipulating or messaging this data, as you can introduce errors that impact the Data Processing and make the Data Out incorrect. You should always remember the warning of a great 20th-century statistician:
"If you torture the data long
enough, it will confess to anything."
- from Darrell Huff's book "How to Lie With Statistics"
(1954)
And make no mistake about it, Data Manipulation and Messaging is a form of torturing the data that can produce desired Data Out rather than correct Data Out.
Problems with Data Processing
- Algorithm Correctness
Algorithms can be incredibly complex in Computer Modeling and Statistical Processing. They are a combination of Constants and Variables, Boolean Logic, and Order of Operations. If you get any of these wrong, then you get the wrong results. The old engineering homily of “Constants won’t, and Variables aren’t” should be remembered by all that create algorithms, as what you think is a constant may be a variable, and what you think is a variable may actually be a constant (usually due to a lack of or incorrect knowledge). - Interrelationship of Algorithms
No computer model or statistical process is one algorithm but a combination of many algorithms. The algorithms have interrelationships and pass data between themselves. If one algorithm is wrong and passes its results to other algorithms, then the receiving algorithm will produce incorrect results from the incorrect passed data, which it can pass on to another algorithm which will produce incorrect results. - Feedback Loops of Dynamic Models
In a dynamic computer model, as the model progresses, it sends data back into the model for additional processing, a process known as feedback. If any of the Data Processing is incorrect, then the feedback only magnifies the incorrectness, and the Data Out will be wrong.
Problems with Data Out
- Verifiability
How can you verify a model, especially when the Data Out computer model is a future projection model? Many times, scientists and engineers create a mockup or scale model based on the Data Out of Computer Modeling and Statistical Processing, then run these creations through extensive testing. If the mockup or scale model passes the test, then they create a full-scale prototype and extensively test the prototype. Only after this testing is successful do they embrace the Computer Model or Statistical Process. Often, however, this cannot be done for complex dynamic models, so they embrace a confidence level factor which in itself can be unreliable. All confidence level factors are based on a human judgment of Data In, Data Processing, and Data Out, and human judgments are subject to improper Reasoning of Formal and Informal Logic, Logical Fallacies, and Cognitive Biases. Consequently, we should all remember that “Fools rush in where Angles fear to tread” when deciding to take actions on a Computer Model or Statistical Process that cannot be verified. - Interpretation
When interpreting the Data Out of Computer Modeling and Statistical Processing, the Data Out should always be, at a minimum, the Best Case, the Worst Case, and the Medium Case of the model, and all such cases should be reported as the possible results of the Computer Model and Statistical Process (especially for dynamic models). To not do so is to mislead those that utilize the Computer Model and Statistical Process, which can lead to extremely unfortunate or dire consequences.
Knowledge and Consensus/Settled Science
"In reality there is nothing
mysterious in this entire universe, there is only our lack of
knowledge!"
- Mehmet Murat Ildan
Knowledge and Consensus/Settled Science is best expressed by the phrase, “That which we know that we know, that which we know that we don't know, and that which we don't know what we don't know”, which is a problem for all of Science, Technology, Engineering, and Mathematics (STEM). This is a significant problem in Computer Modeling and Statistical Processing, as a lack of knowledge, incorrect knowledge, or not knowing what we don’t know will produce incorrect results.
With the great progress of science throughout the last several centuries, there is much that we know and much that we don’t know that we know of. Indeed, we know quite a lot, but we know there is quite a lot that we don’t know. It is the purpose of scientific research to discover the answers to what we don’t know and to reaffirm the answers to what we know. During this process, scientists often discover new things that we did not know existed (i.e., That we didn’t know what we didn’t know) or that what we did know was incorrect or incomplete. It has been estimated that there is much more knowledge that we don’t know exists than the knowledge that has already been obtained, as the following chart illustrates.
The problem with this chart is that it cannot be known how big the slice of ‘Don’t Know What You Don’t Know’ is, as it is unknown. If there are many more unknowns, then the percentage of ‘Know What You Know’ and ‘Know What You Don’t Know’ will be smaller, and if the percentage of ‘Don’t Know What You Don’t Know’ is smaller, then the other percentages will be larger. So, where did these percentage numbers come from? The truth is that I made up these numbers to emphasize that there is much more to what we ‘Don’t Know What You Don’t Know’ than there is of ‘Know What You Know’ and ‘Know What You Don’t Know’. Therefore, it is never possible to know what the correct percentages of these slices are, and:
"Lack of knowledge - that is the
problem."
- W. Edwards Deming
Problems with Know What We Know
“The trouble with the world is not
that people know too little; it's that they know so many things
that just aren't so.”
- Mark Twain
Incomplete or Incorrect knowledge is a given. Even with a team of highly knowledgeable and intelligent persons developing a Computer Model or Statistical Process, there will be gaps in knowledge and knowledge that is incorrect. One of the means to correct this situation is for outside experts to review and critique the Computer Model or Statistical Process. However, many companies and institutions are reluctant to do this, as it would reveal proprietary or trade secrets to competitors, and it might reveal some incompetence on the developer’s part. Thus, resulting in the tarnishing of the reputation of the persons, institutions, or companies and (perhaps unjustly) affecting the reputation of their other efforts.
Problems with Know What We Don’t Know
"To know what you know and what you
do not know, that is true knowledge."
- Confucius
Known unknowns bedevil developers of Computer Models and Statistical Processes. Trying to compensate for these known unknowns through various means introduces errors and uncertainties in a Computer Model and Statistical Process. Much of non-deterministic models are developed to account for these known unknowns, but the data from these non-deterministic models have a range of possible outcomes. A range of possible outcomes makes the utilization of these Computer Models and Statistical Processes for decision-making more problematic and subject to unintended consequences.
Problems with Don’t Know What We Don’t Know
“There are more things in heaven and
earth, Horatio, than are dreamt of in your philosophy.”
- Hamlet.
Unknown unknowns are the backbreaker of Computer Modeling and Statistical Processing. It is that we don't know that we don’t know that is often the killer whenever we computer model or statistical process. All STEM is subject to unknown unknowns, and many calamitous results have occurred in STEM because of unknown unknowns. Thus, all Computer Modeling and Statistical Processing is suspect as what we don't know that we don't know is inherent in STEM.
Scientific Consensus and Settled Science
In my article on Scientific Consensus and Settled Science, I point out the Proverb 'People who live in glass houses shouldn't throw stones' that should always be remembered during any debate or discussion, especially in Science discussions that involve consensus and settled science. Scientific consensus and settled science can lead you astray, as it has been wrong in the past and will continue to be wrong as changed or new knowledge is obtained. Consensus and settled science is an important starting point, but it should be remembered that all scientific consensus and settled science has scientific disputations, as this is the nature of scientific thoughts, investigations, and research. Computer Modeling and Statistical Processing based on consensus science has the inherent problems of scientific consensus and settled science, and the utilization of consensus and settled Science in Computer Models and Statistical Processes will often produce incorrect results that are scientifically disputable. You should also consider the thoughts of the American author and filmmaker Michael Crichton:
“I want to pause here and talk about this notion of consensus, and the rise of what has been called consensus science. I regard consensus science as an extremely pernicious development that ought to be stopped cold in its tracks. Historically, the claim of consensus has been the first refuge of scoundrels; it is a way to avoid debate by claiming that the matter is already settled. Whenever you hear the consensus of scientists agrees on something or other, reach for your wallet, because you're being had.
Let's be clear: the work of science has nothing whatever to do with consensus. Consensus is the business of politics. Science, on the contrary, requires only one investigator who happens to be right, which means that he or she has results that are verifiable by reference to the real world. In science consensus is irrelevant. What is relevant is reproducible results. The greatest scientists in history are great precisely because they broke with the consensus.
There is no such thing as consensus
science. If it's consensus, it isn't science. If it's science, it
isn't consensus. Period.”
- Michael Crichton
When dealing with Knowledge and Consensus/Settled Science, the human foibles of pride, egotism, and hubris often come into play. A good STEM person attempts to minimize or eliminate these foibles in their efforts, but we are all human and subject to human imperfections. We should all remember that:
"There is no shame in ignorance,
only in denying it. By knowing what we do not know, we can take
steps to remedy our lack of knowledge."
- Graham McNeill
Unintended Consequences
In my article on "The Law of Unintended Consequences", I point out that The law of Unintended Consequences, often cited but rarely defined, is that actions of people—and especially of government—always have effects that are unanticipated or unintended in its outcomes. Economists and other social scientists have heeded its power for centuries, and for just as long, politicians and popular opinion have largely ignored it. Most often, however, the law of unintended consequences illuminates the perverse unanticipated effects of government legislation and regulation, as well as the unmindful trust in expert opinion.
Unintended consequences can be grouped into three types:
- Unexpected benefit
A positive unexpected benefit (also referred to as luck, serendipity, or a windfall) that has an advantageous effect. - Unexpected drawback
An unexpected detriment occurs in addition to the desired effect of the policy that has an adverse effect. - Perverse result
A perverse effect is contrary to what was originally intended (when an intended solution makes a problem worse). This is sometimes referred to as 'backfire'.
These unintended consequences impact not only those persons or objects directly impacted but also persons or objects that were not intended to be impacted.
However, the developers and utilizers of Computer Models and Statistical Processes often ignore this law when they utilize the results of the models and processes in making decisions. When utilizing the results of a Computer Model or Statistical Process, there will always be unintended consequences, as the result of the Data In + Data Processing = Data Out and Knowledge and Consensus/Settled Science problems that I previously discussed.
It is the height of hubris to believe that you can determine all the consequences of utilizing a Computer Model or Statistical Process. Nobody can conceive of the unintended consequences of a Computer Model or Statistical Process, especially when a Computer Model or Statistical Process contains errors (which it often does).
Consequently, all must be wary of Computer Models and Statistical Processes, as there will always be unintended consequences when implementing the results of a Computer Model or Statistical Process in the real world.
Conclusions
"All models are wrong, some are
useful."
- George E. P. Box, one of the great statistical minds of
the 20th century
These words of wisdom must be kept in mind whenever you utilize a Computer Model or Statistical Process in decision-making or in its implementation in the real world. The difficulty is determining which Computer Models or Statistical Processes are useful and which are useless. A good rule of thumb (as it pertains to almost all human actions) is that 10% of Computer Modeling and Statistical Processing are useful, while 90% are useless. There is no known way to distinguish the useful from the useless except to rely on knowledgeable, intelligent, and wise persons who have examined the Computer Model or Statistical Process to determine its usefulness. A wise person will also carefully consider the doubters and dissenters of the Computer Model and Statistical Process in determining its usefulness and always caveat their conclusions with a statement and reason for why they may be wrong.
In addition, the above quote is why Computer Models and Statistical Processes cannot be a proof of science. No science is ever confirmed by a computer model, as science is proved by observations and experiments conducted in the real world. It is also unfortunate that some scientists behave as if their Computer Modeling and Statistical Processing are “proofs” of their scientific beliefs when they know it is only an indication that their scientific beliefs may be correct. A good scientist will take the results of their Computer Model and Statistical Process and try to confirm them through observations and experiments conducted in the real world.
Another problem with Computer Models and Statistical Processes is their utilization by non-scientists to advocate for public policies. Too often, the public believes in a computer model, especially when it confirms their beliefs about the real world, and they accept Computer Models and Statistical Processes as “proof” of their beliefs. And unfortunately, most Activists and Activism and politicians for causes that rely on a scientific foundation (e.g., Climate Change, Environmentalism, COVID-19 Pandemic, etc.) accept these Computer Models and Statistical Processes as proof of the correctness of their claims.
We should all remember that “Figures can lie, and liars can figure” as a warning to beware of all who use Computer Models and Statistical Processes to advance their agenda. This was not an indictment of modelers or statisticians; rather, it is a call to use reason and logic and to ask questions and seek understanding when presented with a conclusion based on Computer Models and Statistical Processes. Knowing what is important, what is unimportant, and what is misleading when reviewing Computer Models and Statistical Processes is crucial to discovering the truth. My article, Oh, What a Tangled Web We Weave, examines the various precautions that you should employ when you review Computer Models and Statistical Processes to buttress an argument. As for Scientific Consensus or Settled Science, when someone uses the phrase to buttress their arguments, you can be sure that that person does not understand the true nature of science, and you should be very wary of their arguments.
The biggest example of the problems that I have discussed in this article is the utilization of Computer Modeling and Statistical Processing for Climate Change predictions (a non-deterministic computer model). Climate Change is so incredibly complex, with many inputs, interactions, and feedbacks, as well as incorrect, incomplete, and unknown knowledge, resulting in unintended consequences, that the predictions of Climate Change Computer Models should be viewed with concern.
I believe in climate change, and I have written about my beliefs in my science article on Climate Change. I believe the climate has changed in the past, the climate is currently changing, and the climate will change in the future. This is a meteorological and geological scientific fact. The question is whether human activity is causing current climate change. This may be true or may not be true, depending upon your interpretation of scientific facts and truths. If you have read my Science Article "On the Nature of Scientific Inquiry", you know that I have a scientific orientation to my thinking, and in this article, I apply that scientific thinking to many of the issues and concerns of Climate Change.
My primary concern, as it relates to this article, is the following chart:
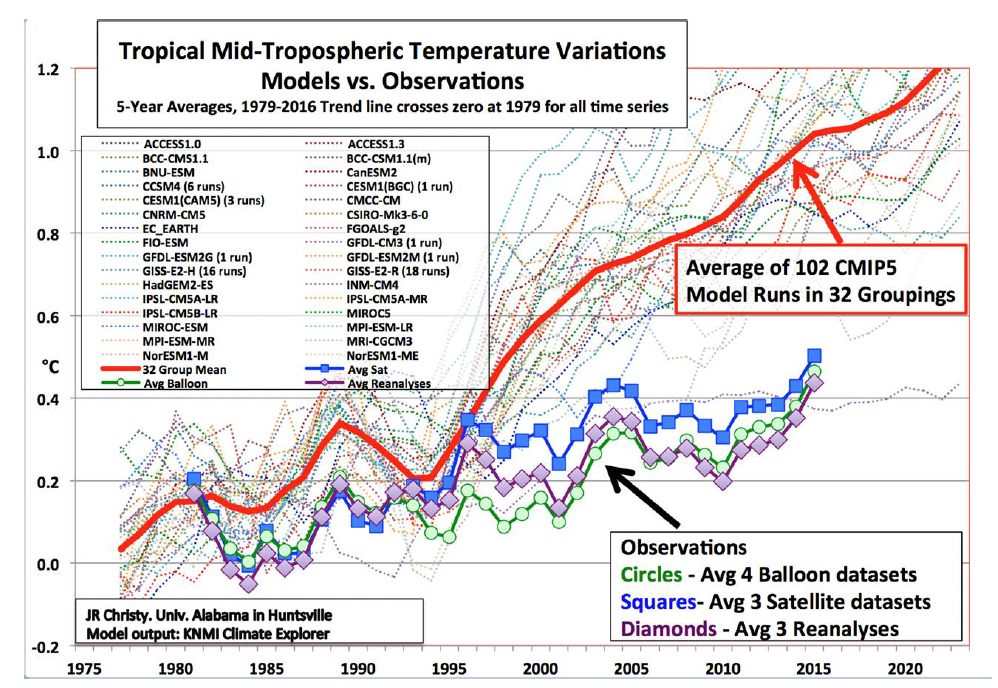
The thick red line is the average of the many computer models' predictions of climate change, while the thin color lines are the predictions of the various Climate Change Computer models, while the green circles and blue squares are actual measurements. This chart not only highlights the average predictions against the realities, which calls into question the correctness of the Computer Models, but it also highlights the disparities between the different Computer Models. If the issues I discussed in this article were minimal or non-existent in Climate Change Computer Models, then there should be no or little disparities between the different Computer Models. The fact of large disparities between the different Climate Change Computer Models calls into question the reliability of the Computer Models. Thus, we must be very careful when using Climate Change Computer Models when instituting climate change policies.
In my article, Computer Modeling, I examine in more specificity the issues, concerns, and limitations when utilizing Computer Models in science and engineering. I do not delve into the details of Computer Modeling, nor do I utilize any sciences or mathematics in examining the issues, concerns, and limitations of computer modeling. However, in this article, I provide more information on computer modeling, with many examples and diagrams to assist the reader in a better understanding of the complexities of Computer Modeling and Statistical Processing.
There are several other problems that beset modern science that impact the use of Computer Modeling and Statistical Processing. The articles that I have written about these other problems are:
The Problems with Modern Science - This article is an Outline of The Problems with Science in the latter half of the 20th century and the 21st century. It is not about the science but the way modern science is pursued. It does not delve into the details of science and utilizes no mathematics but instead highlights the issues regarding Modern Science (post World War II). This paper was written to provide the general public with the background on these problems so that when they encounter public policy issues that utilize science, they will have a basis for interpreting the scientific information.
Scientific Consensus and Settled Science - The Proverb 'People who live in glass houses shouldn't throw stones' should always be remembered during any debate or discussion, especially in scientific discussions. And scientific consensus and settled science can lead you astray, as it has been wrong in the past and will continue to be wrong as new knowledge is obtained. This article examines, in more detail, with examples, the problems of Scientific Consensus and Settled Science.
Orthodoxy in Science - Dissent and Disputation are common in science. When such dissents and disputations occur, it is acceptable to critique the science, but it is unacceptable to criticize the scientists. This tolerance for dissent and disputations, when based upon scientific evidence (or that lack thereof), is healthy for the progress of science and for the betterment of humankind. This article examines a modern trend of Scientific Orthodoxy to criticize the scientists rather than critique the science.